最終更新日: 2025年3月27日
はじめに:Stable Diffusionの魅力と可能性
AIによる画像生成が身近になった今、多くのクリエイターが注目しているのが「Stable Diffusion」です。テキストから画像を生成するこのオープンソースAIは、商用利用可能で無料で使えるという大きな特徴を持っています。
Stable Diffusionは、Midjourney、DALL-E、Firefly等の他のAI画像生成ツールと比較して、以下のような特徴があります:
- 完全無料で使える: 商用利用を含め、基本的に無料で利用可能です
- ローカル実行: 自分のPC上で動作するため、インターネット接続なしでも使用可能
- カスタマイズ性: モデルの変更や拡張機能の追加など、高度なカスタマイズが可能
- プライバシー: 生成内容がサーバーに送信されないため、機密情報を含む画像も安心して生成できる
しかし、その高い自由度と引き換えに、初心者にとってはインストールや設定に少しハードルがあります。この記事では、Windows PCでのStable Diffusion Web UIのインストールから初めての画像生成まで、ステップバイステップで解説します。
この記事を読むことで、あなたは以下のことができるようになります:
- Stable Diffusion Web UIを自分のPCにインストールする
- 基本的な設定と日本語化を行う
- 簡単なプロンプトで最初の画像を生成する
- モデルの追加と切り替えを行う
- 便利な拡張機能を導入する
さあ、Stable Diffusionの世界へ踏み出しましょう。
事前準備:必要なスペックとセットアップ
推奨PC要件
Stable Diffusionをスムーズに動作させるためには、以下のようなスペックが推奨されます:
| コンポーネント | 最低要件 | 推奨要件 | 備考 |
|---|---|---|---|
| GPU | NVIDIA GeForce GTX 1060 6GB | NVIDIA GeForce RTX 3060以上 | AMDやIntel GPUも対応していますが、NVIDIAが最も安定 |
| VRAM | 6GB | 8GB以上 | 高解像度や複雑なモデルには12GB以上が望ましい |
| RAM | 8GB | 16GB以上 | システム全体の安定性に影響 |
| ストレージ | 20GB HDD | 50GB以上 SSD | モデル追加で数十〜数百GBになることも |
| CPU | Core i5 / Ryzen 5 | Core i7 / Ryzen 7以上 | GPUが主に使われるため、最重要ではない |
| OS | Windows 10 64bit | Windows 10/11 64bit | Linux/macOSも対応していますが、この記事ではWindows向けに解説 |
お使いのPCが最低要件を満たさない場合や、手軽に試したい場合は、以下の代替手段があります:
代替手段:Google Colabやクラウドサービス
- Google Colab:
- 無料でGPUを使用可能なクラウド環境
- Stable Diffusion Web UI for Colabなどのノートブックを利用
- 無料版は継続的な使用に制限あり
- Paperspace Gradient:
- 従量課金制のクラウドGPUサービス
- 設定済みのStable Diffusionテンプレートあり
- 月額料金+使用量に応じた課金
- RunPod/Vast.ai:
- GPU時間課金制のクラウドサービス
- 高性能GPUを一時的に借りられる
- コスト効率が良い選択肢
ローカルインストールの前に必要なソフトウェア:
- Python 3.10.x(3.11以降は互換性の問題が生じる可能性あり)
- Git(GitHub からのクローンに必要)
- Visual C++ 2019 Redistributable
では、これらを事前に準備した上で、インストール手順に進みましょう。
インストール方法(Windows向け詳細ガイド)
Step 1: Pythonのインストール
- Python公式サイトから「Python 3.10.9」をダウンロード
- 「Windows installer (64-bit)」を選択
- インストーラーを実行し、以下の設定を行う
- 「Add Python 3.10 to PATH」にチェックを入れる(重要)
- 「Install Now」をクリック
- インストール完了後、コマンドプロンプトを開き、以下のコマンドで確認
python --version「Python 3.10.9」と表示されれば成功です。
Step 2: Gitのインストール
- Git公式サイトから「Git for Windows」をダウンロード
- インストーラーを実行し、基本的にはデフォルト設定のまま進める
- インストール完了後、以下のコマンドで確認
git --versionStep 3: Visual C++ 2019 Redistributableのインストール
- Microsoft公式サイトからダウンロード
- インストーラーを実行し、画面の指示に従ってインストール
Step 4: Stable Diffusion Web UIのクローンとインストール
- コマンドプロンプトを管理者権限で開く
- インストール先のフォルダに移動(例:Dドライブに「AI」フォルダを作成する場合)
D:
mkdir AI
cd AI- GitHubからStable Diffusion Web UIをクローン
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git- クローンしたフォルダに移動
cd stable-diffusion-webuiwebui-user.batファイルをメモ帳で開き、以下の行を追加(NVIDIAのGPUを持っている場合)
set COMMANDLINE_ARGS=--xformersメモリが少ない場合は、以下も追加すると良いでしょう:
set COMMANDLINE_ARGS=--xformers --medvramStep 5: Web UIの起動
webui-user.batをダブルクリックして実行- 初回起動時は必要なライブラリやモデルのダウンロードが自動的に行われる(15-30分程度かかることがあります)
- 処理が完了すると、ブラウザが自動的に開き、
http://127.0.0.1:7860にアクセスされる
これでStable Diffusion Web UIのインストールは完了です!
Step 6: 日本語化(オプション)
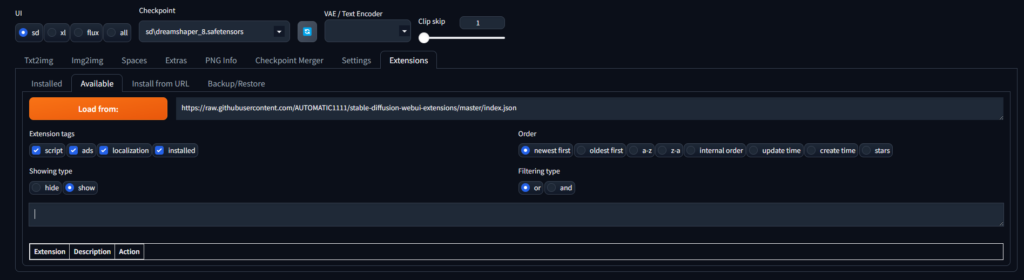

- Web UIの上部メニューから「Extensions」タブをクリック
- 「Available」タブを選択
- 検索欄に「localization」と入力
- 「Stable Diffusion Web UI Localization」を見つけて「Install」をクリック
- インストール完了後、「Installed」タブに移動し「Apply and restart UI」をクリック
- Web UIが再起動したら、上部メニューの「Settings」タブをクリック
- 左側のメニューから「User interface」を選択
- 「Localization」セクションで「ja_JP」を選択
- 下にスクロールして「Apply settings」→「Reload UI」をクリック
これで日本語化は完了です。
基本的な使い方:Web UIの主要機能
インターフェースの基本構成
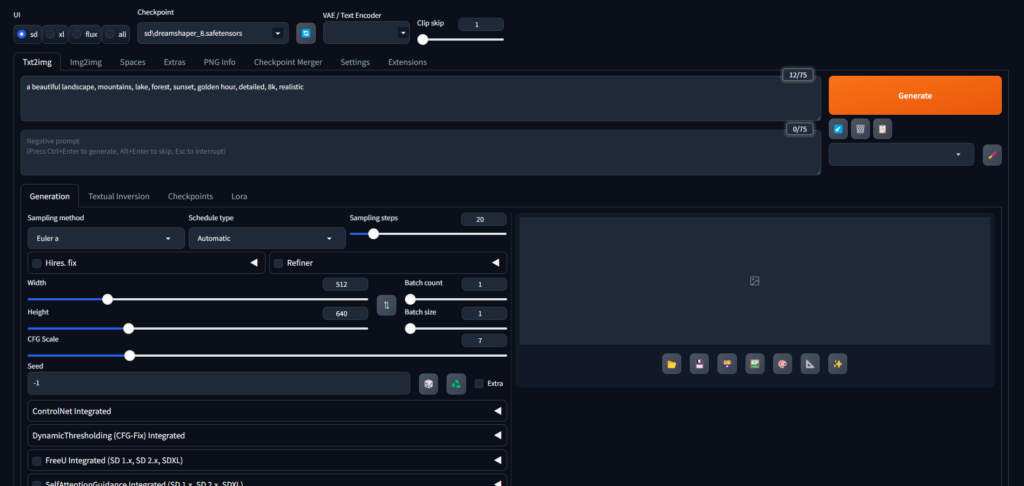
Stable Diffusion Web UIのメインインターフェースは、大きく以下のセクションに分かれています:
- txt2img/img2img タブ:
- txt2img: テキストから画像を生成
- img2img: 元画像を基に新しい画像を生成
- 左側パネル:
- プロンプト入力欄: 生成したい画像の説明
- ネガティブプロンプト入力欄: 避けたい要素の説明
- 生成パラメータ(サイズ、サンプリングメソッド、ステップ数など)
- 「生成」ボタン
- 右側パネル:
- 生成された画像の表示エリア
- 画像操作ボタン(保存、拡大表示など)
- 生成情報(シード値、プロンプト、設定など)
- 上部メニュー:
- Extras: 画像の後処理
- PNG Info: 画像のメタデータ表示
- Settings: 詳細設定
- Extensions: 拡張機能の管理
- など
基本設定の最適化
初期設定のままでも使えますが、以下の設定を調整することで、より良い結果を得られます:
- 設定タブ > Stable Diffusion:
- 「CLIP skip」を2に設定(日本語アニメ系モデルで推奨)
- 設定タブ > インターフェース:
- 「保存形式の選択」を「原義のガイド」に設定
- 「プロンプトとネガティブプロンプトに異なるテキスト領域を使用する」をオン
- 「カード幅とギャップのサイズ」を好みに応じて調整
- 設定タブ > パフォーマンス:
- 「Use Torch Compile」をオン(RTX 4000以降のGPUで推奨)
- 「VAEを可能な限りCPU上で実行する」を、品質重視ならオン、速度重視ならオフ
設定変更後は必ず「Apply settings」→「Reload UI」をクリックして適用してください。
プリセットの活用方法
頻繁に使う設定の組み合わせは、プリセットとして保存しておくと便利です:
- 設定(サンプリング方法、ステップ数など)を調整
- 左下の「プリセット」エリアでプリセット名を入力
- 「保存」ボタンをクリック
- 次回使用時は、プリセットのドロップダウンから選択
最初の画像生成:簡単なプロンプト作成
基本的なプロンプトの書き方

プロンプトは、生成したい画像を言葉で表現したものです。英語で記述するのが基本ですが、日本語でも一定の結果が得られます。
基本的な書き方:
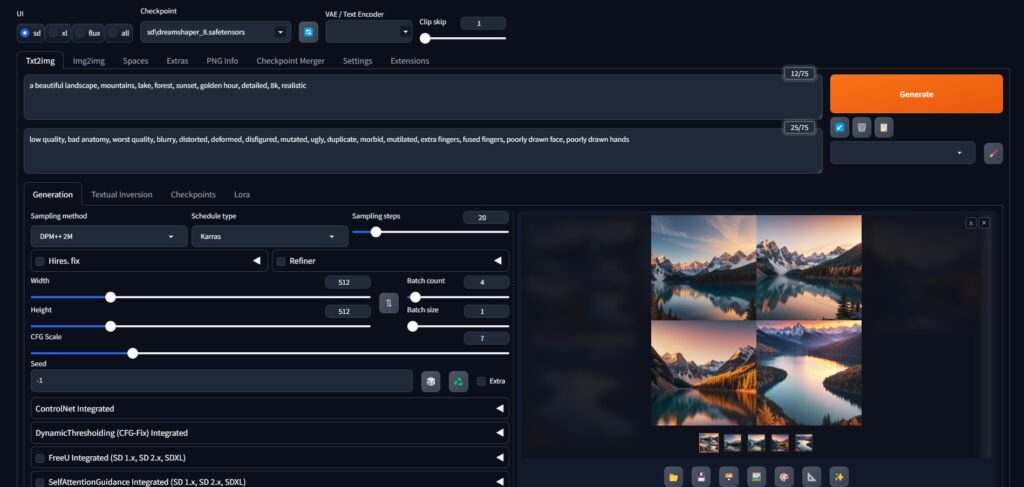
主題, 詳細な説明, スタイル, 雰囲気, 光の状態例:
a beautiful landscape, mountains, lake, forest, sunset, golden hour, detailed, 8k, realisticプロンプトのコツ:
- 具体的に書く:「beautiful」より「stunning alpine landscape with snow-capped peaks」の方が具体的
- 重要な要素を最初に:最初に書いた要素ほど強く反映される傾向がある
- カンマで区切る:要素同士はカンマで区切るのが一般的
- 重みづけを使う:
(important element:1.5)のように括弧内に重みづけができる(1.0が基準)
ネガティブプロンプトの効果的な使用
ネガティブプロンプトは、生成結果から排除したい要素を指定します。
よく使われるネガティブプロンプト例:
low quality, bad anatomy, worst quality, blurry, distorted, deformed, disfigured, mutated, ugly, duplicate, morbid, mutilated, extra fingers, fused fingers, poorly drawn face, poorly drawn hands初心者は、まず上記のような基本的なネガティブプロンプトを使い、徐々に自分好みにカスタマイズしていくと良いでしょう。
推奨パラメータの初期設定
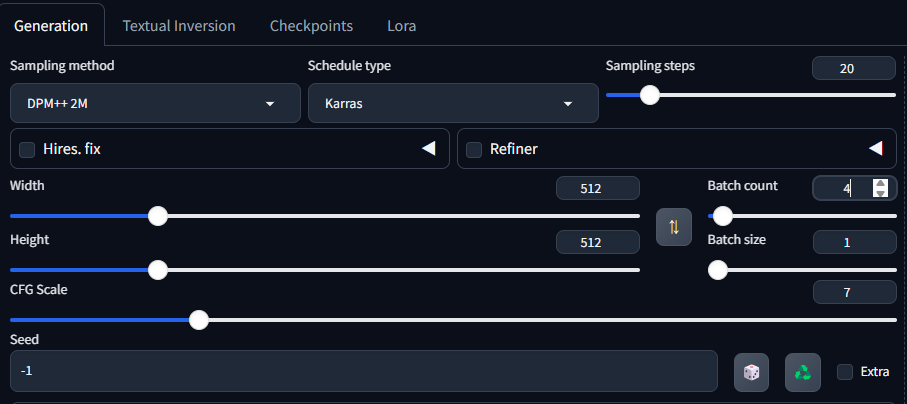
初めての生成には、以下のパラメータがおすすめです:
| パラメータ | 推奨値 | 備考 |
|---|---|---|
| サンプリング方法 | DPM++ 2M Karras | バランスの良いサンプラー |
| サンプリングステップ | 20-30 | 多いほど品質向上だが時間がかかる |
| 幅 x 高さ | 512 x 512 | 標準的なサイズ(GPUに余裕があれば大きくしても良い) |
| CFG Scale | 7 | プロンプト忠実度(高いほどプロンプトに忠実) |
| バッチサイズ | 1 | 初心者は1から始めるのがおすすめ |
| バッチカウント | 4 | 一度に生成する画像数 |
| シード | -1 | ランダム(特定の値を入れると結果が再現可能) |
これらの設定で「生成」ボタンをクリックすると、最初の画像が生成されます。気に入った画像ができたら、その下に表示されるシード値をメモしておくと、同じ構図で微調整することが可能です。
モデルの追加と管理
主要モデルの紹介と選び方
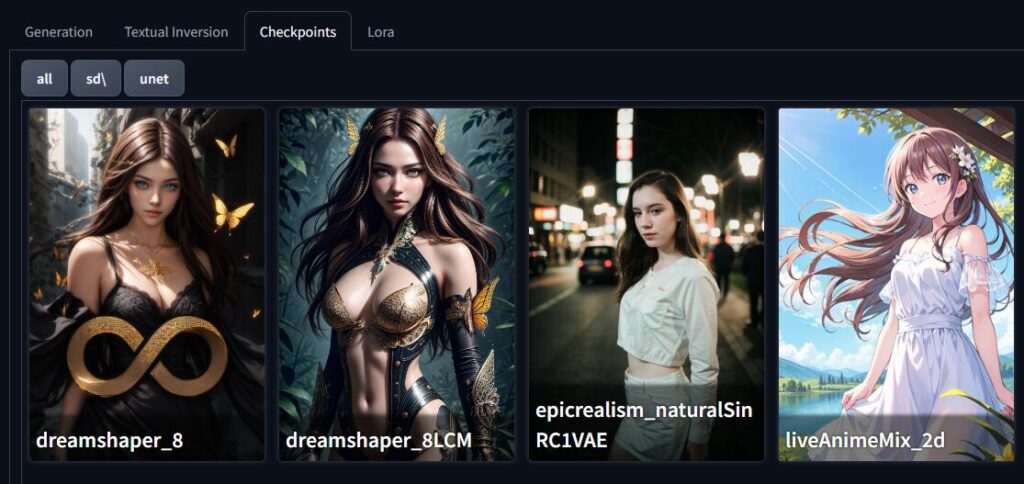
Stable Diffusionには様々なモデル(Checkpoint)があり、それぞれ得意なテイストが異なります。主な種類は以下の通りです:
- 汎用モデル:
- Stable Diffusion基本モデル(v1.5, v2.1など)
- Deliberate, Dreamshaper, Realismなど
- アニメ・イラスト系:
- Anything, AnythingV5
- Counterfeit, Waifu Diffusion
- AbyssOrangeMix, Pastel Mix
- 写実的な人物・風景:
- Realistic Vision
- MajicMix Realistic
- SDXL Base
初心者におすすめのモデル:
- Deliberate v2:汎用性が高く、多くのスタイルに対応
- Anything V5:日本アニメ風の絵柄に特化
- RealisticVision V5.1:リアルな人物写真に強い
モデルのダウンロードと追加方法
モデルは主に以下のサイトから入手できます:
モデルの追加手順:
- モデルファイル(.safetensors/.ckpt)をダウンロード
- ダウンロードしたファイルを以下のフォルダに配置:
[インストールフォルダ]\stable-diffusion-webui\models\Stable-diffusion- Web UIを再起動する(または上部の🔄ボタンをクリック)
- 左側パネルの「Stable Diffusion checkpoint」ドロップダウンから新しいモデルを選択
注意点:
.safetensors形式の方が.ckpt形式よりも安全性が高いため推奨- モデルは数GB程度のサイズになるので、ダウンロードに時間がかかります
- すべてのモデルがすべてのバージョンのWeb UIで動作するわけではありません
モデル切り替えとメモリ管理
複数のモデルを使い分ける際の注意点:
- メモリ使用量:
- モデルの切り替えにはVRAMが必要
- VRAMが少ない場合は「設定 > パフォーマンス」で「モデルをロードしたまま前処理」をオフに
- VAE(Variational Auto-Encoder):
- 多くのカスタムモデルは専用のVAEを推奨
- VAEファイルは
models/VAEフォルダに配置 - 「設定 > Stable Diffusion」で「VAE」を「Automatic」または特定のVAEに設定
- モデル情報の確認:
- Civitaiなどのサイトでモデルの推奨設定を確認
- 特にCLIP skip値、CFG値、サンプラーなどの推奨値に注意
便利な拡張機能TOP5
1. ControlNet – 構図や姿勢の制御
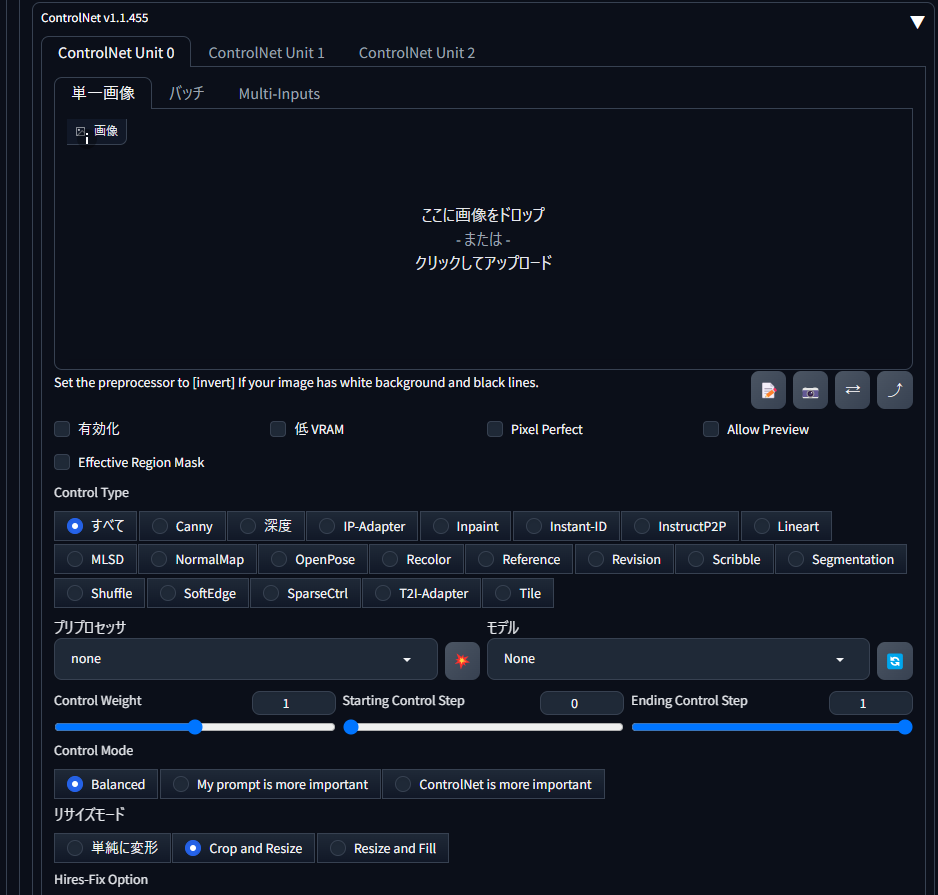
機能:
- 元画像の線画、深度、ポーズなどの情報を維持しながら画像生成
- 特定の構図やポーズを保ちつつ、スタイルや内容を変更可能
インストール方法:
- 「Extensions」タブ > 「Available」タブ
- 検索欄に「controlnet」と入力
- 「ControlNet」を見つけて「Install」をクリック
- インストール完了後、「Apply and restart UI」をクリック
使い方:
- txt2imgタブの下に「ControlNet」セクションが追加される
- 「Enable」をオン
- ドロップダウンからコントロールタイプを選択(Canny、OpenPose、Depthなど)
- 元画像をアップロード
- 「プレプロセッサを実行」をクリック
- 通常通りプロンプトを入力して生成
2. Image Browser – 生成画像の管理
機能:
- 生成した画像をギャラリー形式で閲覧
- 画像の検索、フィルタリング、整理
インストール方法:
- 「Extensions」タブ > 「Available」タブ
- 検索欄に「image browser」と入力
- 「Image Browser」を見つけて「Install」をクリック
- インストール完了後、「Apply and restart UI」をクリック
使い方:
- 上部メニューに「Image Browser」タブが追加される
- フォルダツリーから閲覧したいフォルダを選択
- サムネイルをクリックして画像を閲覧
- 検索バーでプロンプト内容などから検索可能
3. Dynamic Prompts – プロンプトのバリエーション
機能:
- プロンプト内でランダム要素や選択肢を使用可能
- 一度に多様なバリエーションを生成できる
インストール方法:
- 「Extensions」タブ > 「Available」タブ
- 検索欄に「dynamic」と入力
- 「Dynamic Prompts」を見つけて「Install」をクリック
- インストール完了後、「Apply and restart UI」をクリック
使い方:
- プロンプト入力欄で以下のような記法を使用:
{cat|dog|bird}:いずれかをランダムに選択{2$$adjective$$} landscape:形容詞を2つランダムに選択
- txt2imgタブの下に「Dynamic Prompts」セクションが追加される
- 「Enable Dynamic Prompts」をオン
- 通常通り生成
4. Additional Networks – LoRAモデルの管理
機能:
- LoRA(Low-Rank Adaptation)モデルの簡単な管理と適用
- 少ないストレージで特定のスタイルや被写体を追加できる
インストール方法:
- 「Extensions」タブ > 「Available」タブ
- 「additional networks」を検索
- 「Additional Networks for SD WebUI」をインストール
使い方:
- LoRAファイル(.safetensors)を
models/Loraフォルダに配置 - txt2imgタブの下に「Additional Networks」セクションが表示される
- 「Enable」をオン
- モデルをクリックして選択
- 「Add to prompt」で強度とともにプロンプトに追加
5. Prompt Shortcut – プロンプトテンプレートの保存
機能:
- よく使うプロンプトやネガティブプロンプトを保存
- ショートカットで簡単に呼び出し可能
インストール方法:
- 「Extensions」タブ > 「Available」タブ
- 「prompt shortcut」を検索
- 「Prompt Shortcut」をインストール
使い方:
- 「Prompt Shortcut」タブが追加される
- 「Add」をクリックして新しいショートカットを追加
- 名前とプロンプト内容を入力
- プロンプト入力欄で
/[ショートカット名]と入力すると展開される
トラブルシューティング:よくある問題と解決法
メモリ不足エラーの対処
症状:「CUDA out of memory」などのエラーが表示される
解決策:
- 「設定 > パフォーマンス」で以下の設定を変更:
- 「切れ目のない操作を可能にする」をオフ
- VRAMに応じて「–medvram」または「–lowvram」オプションを有効化
- 生成設定の変更:
- 画像サイズを小さくする(512×512など)
- バッチサイズを1に減らす
webui-user.batファイルに以下のオプションを追加:
set COMMANDLINE_ARGS=--xformers --opt-sub-quad-attention --medvram起動しない場合の確認点
症状:webui-user.batを実行してもWeb UIが起動しない
解決策:
- コマンドプロンプトのエラーメッセージを確認
- よくある原因と対策:
- Pythonバージョンの問題:Python 3.10.x(3.11は非推奨)を使用
- パスの問題:インストールパスに日本語や特殊文字が含まれていないか確認
- 権限の問題:管理者権限でコマンドプロンプトを開いて実行
- 依存関係エラー:
update-all.batを実行して依存関係を更新
webui-user.batに以下を追加してデバッグログを有効化:
set COMMANDLINE_ARGS=--debug画像生成の遅さを改善する方法
状況:画像生成に時間がかかり過ぎる
解決策:
- 設定の最適化:
- サンプリングステップ数を減らす(20以下)
- より速いサンプラーを使用(Euler a, DPM++ 2M SDE Karrasなど)
- 「Use Torch Compile」を有効化(RTX 4000以降のGPUで有効)
- ハードウェアの最適化:
- GPUのドライバーを最新版に更新
- 不要なバックグラウンドプロセスを終了
- PCの電源プランを「高パフォーマンス」に設定
- モデルサイズの検討:
- 軽量なモデルの使用(フルサイズより小さい「pruned」モデル)
- 生成時に不要な拡張機能をオフに
次のステップ:スキルアップのロードマップ
Stable Diffusionの基本を習得したら、次のステップとして以下のスキルを段階的に身につけていくことをおすすめします:
1. プロンプトエンジニアリングの深化
- プロンプト辞典サイトなどでプロンプトの書き方を学ぶ
- 特定のアーティストやスタイルの研究
- プロンプト用の単語集を作成
- 自分好みのネガティブプロンプトの洗練
2. ワークフローの高度化
- ControlNetの高度な活用(複数のコントロールを組み合わせる)
- img2img機能でラフスケッチからの展開
- Inpaintingによる部分的な修正や差し替え
- Upscalerを使った高解像度化
3. モデルへの理解を深める
- 異なるモデルの特性の把握
- LoRA、Textual Inversion、Hypernetworkの違いと使い分け
- モデルのマージと調整
- 自分のデータセットでの学習(Dreambooth、LoRA Training)
4. コミュニティへの参加
- Stable Diffusion Discord
- Civitaiのコミュニティ機能
- 日本語コミュニティ(TwitterなどのSNS)
- 生成結果の共有と意見交換
まとめ:Stable Diffusionで広がるクリエイティブの可能性
本記事では、Stable Diffusion Web UIのインストールから基本的な使い方、モデルの追加、便利な拡張機能まで解説しました。
Stable Diffusionは無料で利用できる強力なAI画像生成ツールであり、以下のような特徴があります:
- 無制限に使用可能: 商用利用も含め、基本的に制限なく使える
- 高度なカスタマイズ性: 自分好みにモデルや設定を調整できる
- 拡張性: 様々な拡張機能で機能を追加できる
- コミュニティの支援: 世界中の開発者やクリエイターによる継続的な改良
初めのうちは設定や用語に戸惑うこともあるかもしれませんが、少しずつ実験と学習を重ねることで、あなただけの創造的なワークフローを確立できるでしょう。
AIツールはあくまでもクリエイターの表現を助けるものです。あなた自身のアイデアやビジョンと組み合わせることで、これまでにない創造的な作品を生み出せることでしょう。
Stable Diffusionの世界を探検し、AIとクリエイティビティの可能性を広げていってください!
よくある質問
Stable DiffusionはMacでも使えますか?
はい、Macでも使用できます。特にApple Silicon(M1/M2/M3)チップ搭載のMacではMPS(Metal Performance Shaders)を使用して比較的高速に動作します。インストール方法はWindowsとは異なりますが、公式GitHubリポジトリのMac向け指示に従うことで設定可能です。ただし、NVIDIAのGPUほどのパフォーマンスは期待できません。
生成した画像の著作権は誰に帰属しますか?
Stable Diffusionで生成した画像の著作権法上の扱いは国や地域によって異なります。Stable Diffusionの使用許諾では、生成した画像はあなた自身に帰属するとされています。しかし、特定の有名キャラクターやブランドの特徴を強く出した画像は、既存の著作権や商標権の問題が生じる可能性があります。商用利用する場合は、法的リスクを考慮し、専門家に相談することをおすすめします。
生成画像の品質を向上させるコツはありますか?
画質向上のポイントは以下の通りです:
1. サンプリングステップ数を増やす(30〜50)
2. 高品質を示すキーワードを入れる(high quality, detailed, sharp focus など)
3. 適切なモデルを選ぶ(生成したい画風に合ったもの)
4. VAEを適切に設定する(特に肌の色や彩度に影響)
5. Upscalerで高解像度化
6. Hires.fixオプションを活用
特にプロンプトの書き方と適切なモデル選択が大きく影響します。
Stable DiffusionとMidjourneyの違いは何ですか?
主な違いは以下の点です:
1. 実行環境:Stable Diffusionはローカル実行可能、Midjourneyはクラウドのみ
2. 費用:Stable Diffusionは基本無料、Midjourneyは有料サブスクリプション
3. カスタマイズ性:Stable Diffusionは高度なカスタマイズが可能、Midjourneyは限定的
4. 使いやすさ:Midjourneyはより直感的で簡単、Stable Diffusionは設定が複雑
5. 画質の傾向:Midjourneyは芸術的で一貫性がある、Stable Diffusionはモデルにより様々
自分のニーズや予算、技術的スキルに応じて選択するとよいでしょう。
safetensorsとckptの違いは何ですか?
safetensorsとckptはStable Diffusionのモデルファイル形式です:
.safetensors:
– より安全性が高い(悪意のあるコードが実行されるリスクが低い)
– ロード速度が速い
– メモリ効率が良い
.ckpt:
– 従来からあるPythonのcheckpoint形式
– 任意のコードを含む可能性があり、セキュリティリスクがある
– 互換性は高い
現在は安全性の観点から.safetensors形式が推奨されています。
著者プロフィール: AIクリエイターズハブ編集部
連絡先: お問い合わせフォーム
最終更新日: 2025年3月27日
AIクリエイティブスキルを磨きたいあなたへ(準備中)
最新のAIツール活用法や実践テクニックを定期的にお届けする無料メールマガジンに登録しませんか?
- ✅ 最新AIツールのレビューと活用法
- ✅ プロンプトエンジニアリングの実践テクニック
- ✅ 収益化のためのステップバイステップガイド
さらに、登録者限定で「AIプロンプトテンプレート集(PDF)」をプレゼント!無料メールマガジンに登録する